Understanding the relevance and usefulness of data is essential to answer scientific enquiries. Many data scientists embark on a career in life sciences to solve complex problems with machine learning algorithms with huge potential for humanity.
Disappointingly, this is often not the case and current approaches to data science in biology are not scalable. Many companies hire data scientists without a suitable infrastructure in place to derive value from their work.
The infrastructure challenge is compounded by the need to collaborate with biologists on projects where their roles and responsibilities differ, as do their skills, backgrounds and the tools they use.
Life science companies also require a clear, reproducible and traceable path from business decisions back to compliant, data-driven evidence and the methods and environments that produced them, which provides the third dimension to the data science scalability challenge.
e[datascientist] data science applications address each of the key challenges (infrastructure, collaboration and traceability), liberating the data scientist to conduct higher value work.
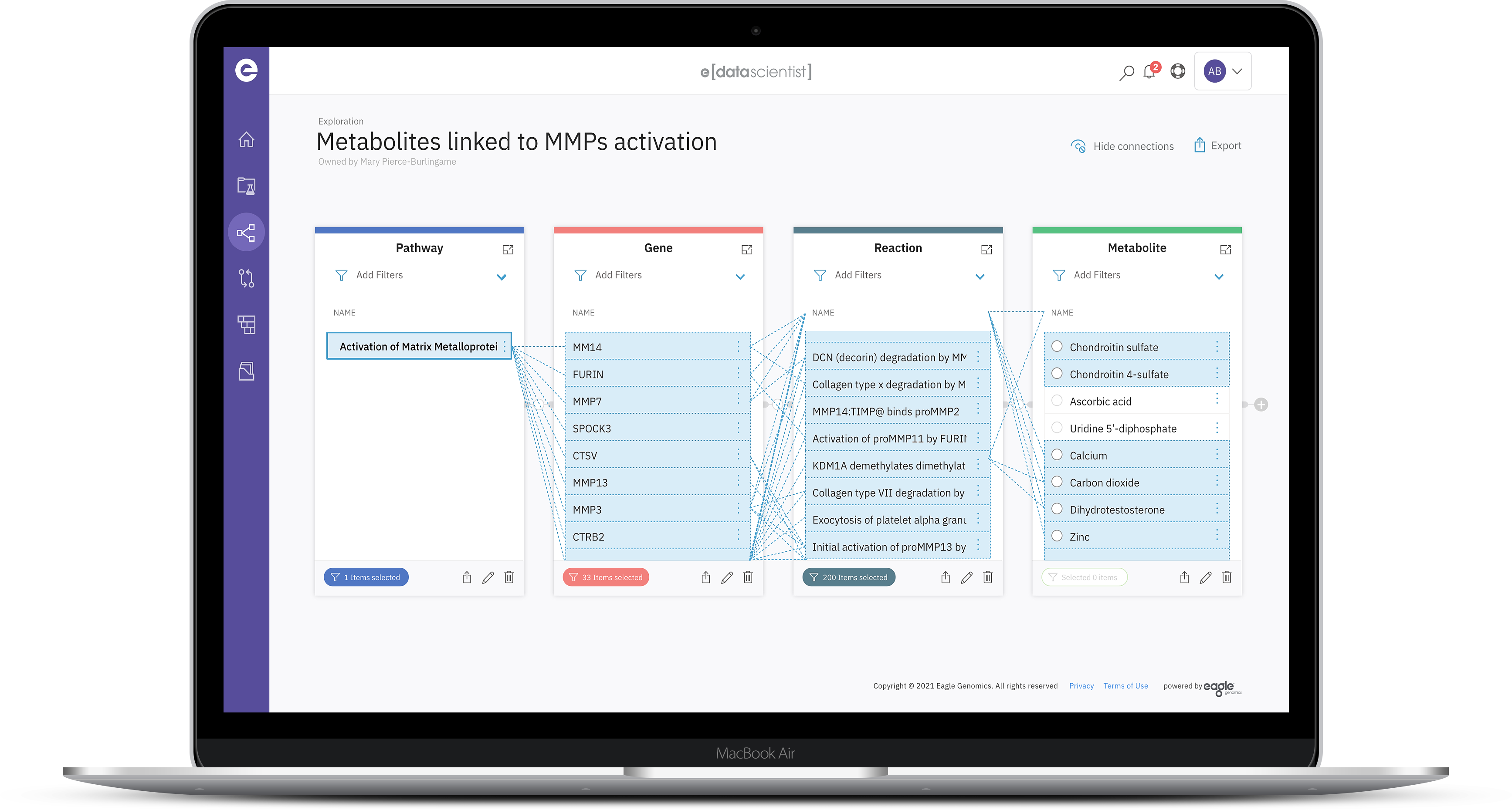
The e[datascientist] data fabric provides a new foundation for semantically rich entity relationship representation of relevant data in a multi-layer hypergraph. Within the design relationships are n-ary (linking two or more entities), have roles within relationships and attributes that are represented as proper objects within the data model.
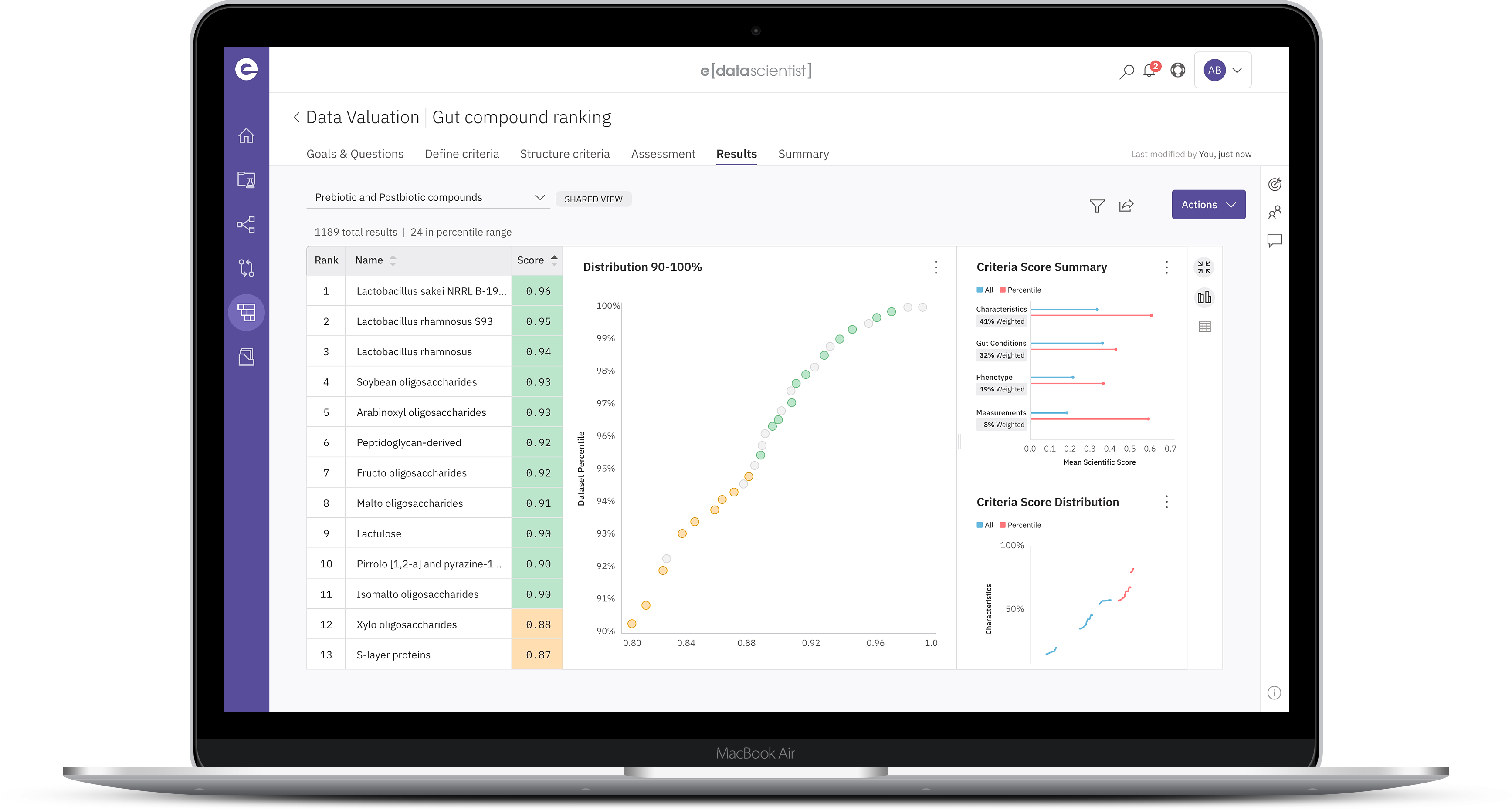
e[datascientist] data science applications enable the acceleration and semi-automation of data curation, the establishment of enterprise valuation models and the instantiation of guided and biology context-specific statistical analysis, ensuring best practice in multi-criteria decision making.
Systematize and automate data curation. Semantically enrich and contextualize data. Structure data and knowledge entities and relationships on the multi-layer hypergraph. Achieve data governance by design through adherence to reference data and ontologies.
Collaborative multi-criteria decision making engine to select, prioritize and optimize understanding of entity relationships. Customize automated data-driven valuation models to capture and test provisional hypotheses.
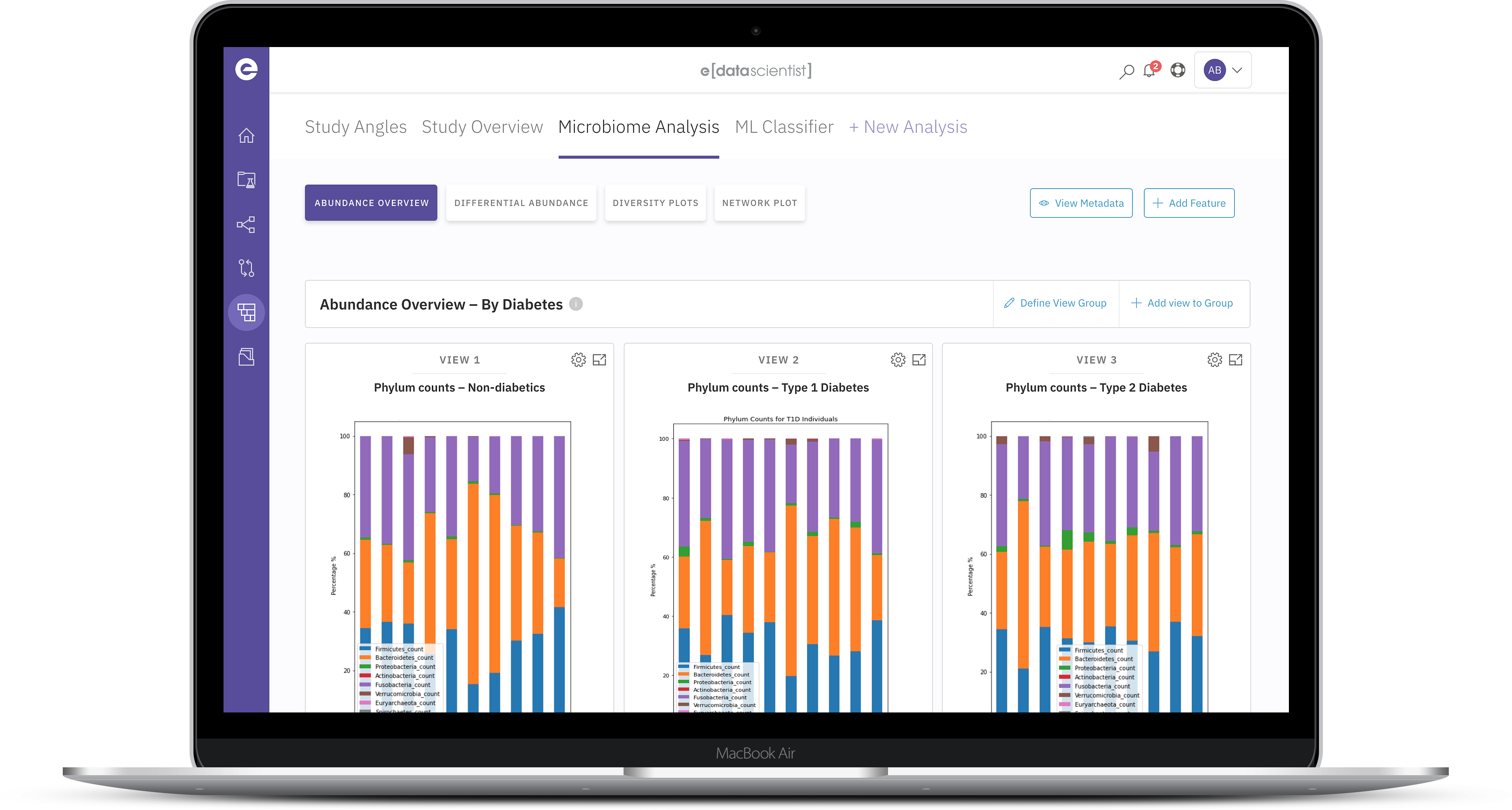
Recommendations and guidance through the entire statistical thinking process. Formulate appropriate hypothesis tests and select relevant statistical tools based on data types and structure on the multi-layer hypergraph.
Eagle Genomics’ innovative approach in establishing a platform-driven ecosystem for the generation and exchange of scientific data-derived assets is of great potential value to Unilever.
Healthy animals, healthy people and a healthy planet are all interconnected. With the advanced knowledge and insights we anticipate generating from our microbiome data, the e[datascientist] will allow us to bring more relevant products to market.
As a company driven by innovation, Reckitt collaborates with partners who bring powerful new capabilities to the table so we can deliver disruptive ideas to the market.