Brands are currently running pipelines in siloed, unstructured environments, and these pipelines are often used without maintaining any biological context.
It is difficult to ensure pipeline scalability and reliability, as these pipelines require significant computation, monitoring, re-starting and troubleshooting.
There is a pressing need for reliable computing resources that do not affect pipeline time execution.
e[pipeline] automates and scales biological pipelines in a context-aware environment.
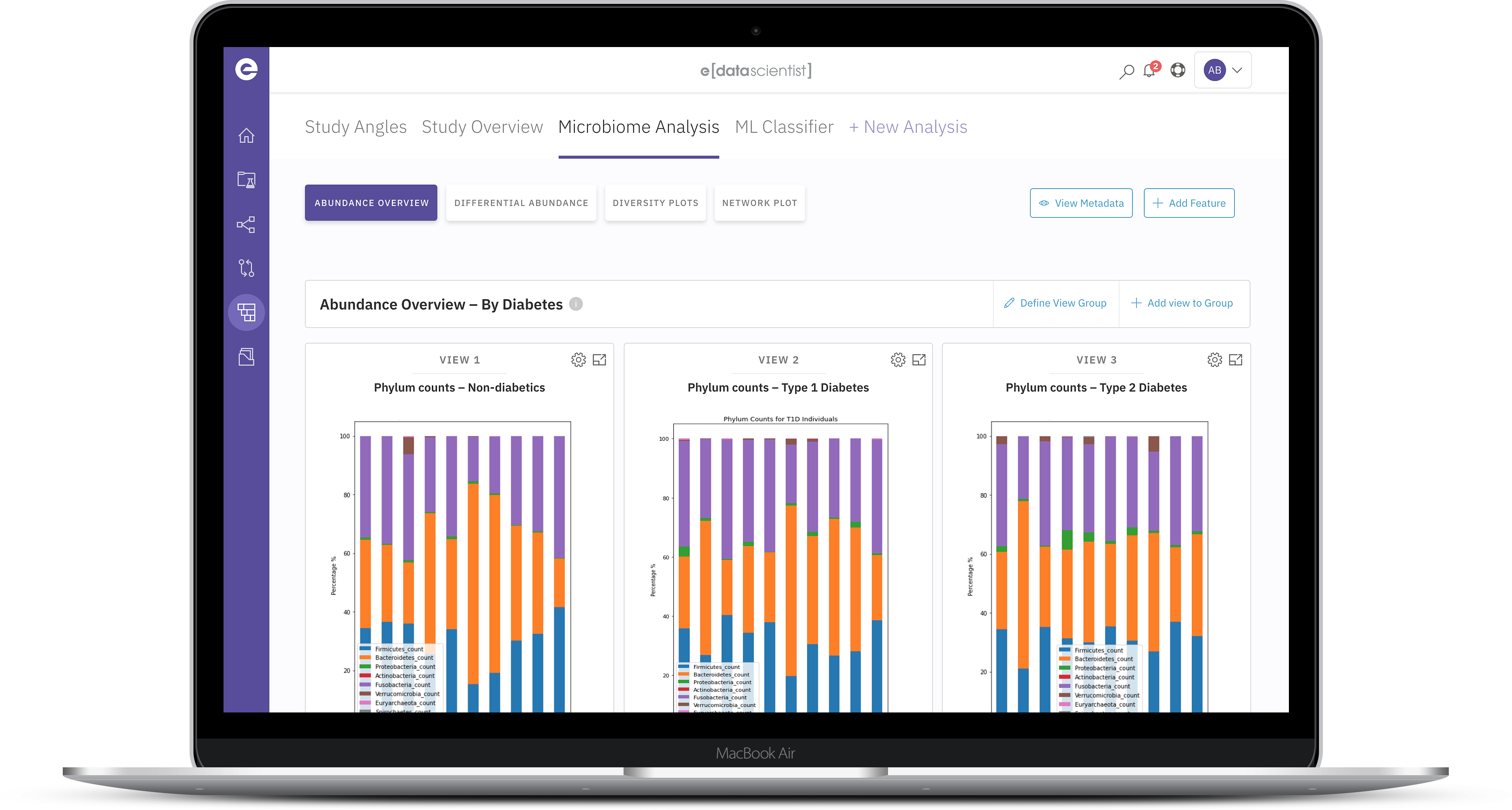
Use, maintain and share pipelines specific to data types (e.g. metagenomic, transcriptomic, metabolomic)
Run pre-configured or customized data pipelines within the platform in a context-aware environment
Link outputs of pipeline runs to extensive downstream analyses (e.g. non-linear regression, multi-omics, network metrics, enrichment analysis, etc.)
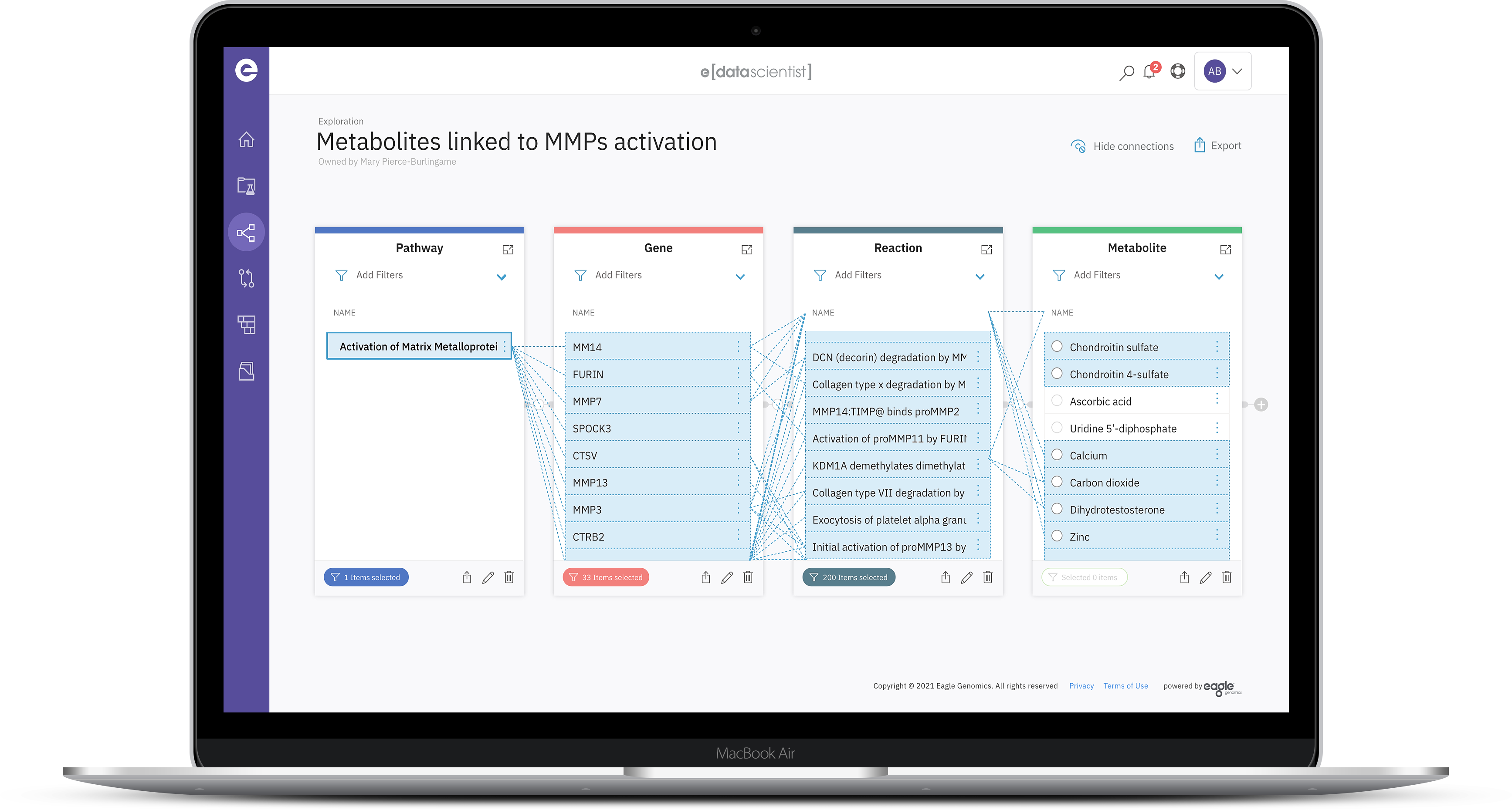
Explore outputs from pipeline results and link them with further biological context (e.g. host interactions, links to diseases or indications, health benefits, etc.) via the multi-layer hypergraph
Export comprehensive reports within minutes, delivering traceability and transparency, and enabling more effective collaboration
Run key pipelines with automatically managed computational demands
Edit and amend pipelines in real time, based on data context and specific research objectives
Access a comprehensive overview of pipeline activities and results, identifying and visualizing emerging relationships in data
Extend workflows beyond pipeline runs, linking results to other experiments and biological outcomes, and expanding the frame for insight and knowledge discovery
Eagle Genomics’ innovative approach in establishing a platform-driven ecosystem for the generation and exchange of scientific data-derived assets is of great potential value to Unilever.
Healthy animals, healthy people and a healthy planet are all interconnected. With the advanced knowledge and insights we anticipate generating from our microbiome data, the e[datascientist] will allow us to bring more relevant products to market.
As a company driven by innovation, Reckitt collaborates with partners who bring powerful new capabilities to the table so we can deliver disruptive ideas to the market.