Applications
Select, combine and compose applications that best apply to your scientific journey.
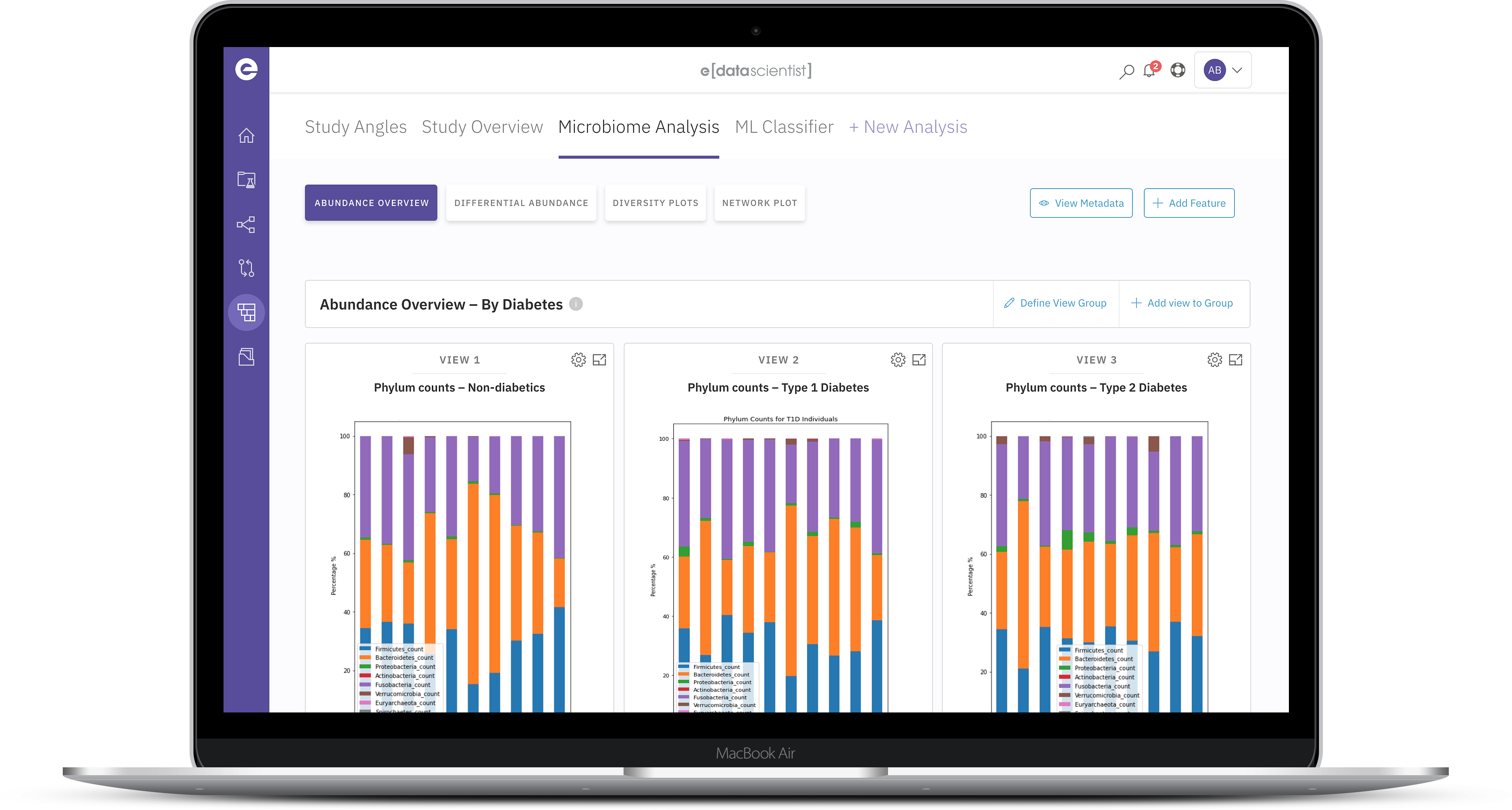
Augment the internal data estate with an industry-defining data universe designed to accelerate collaborative innovation in the microbiome space.
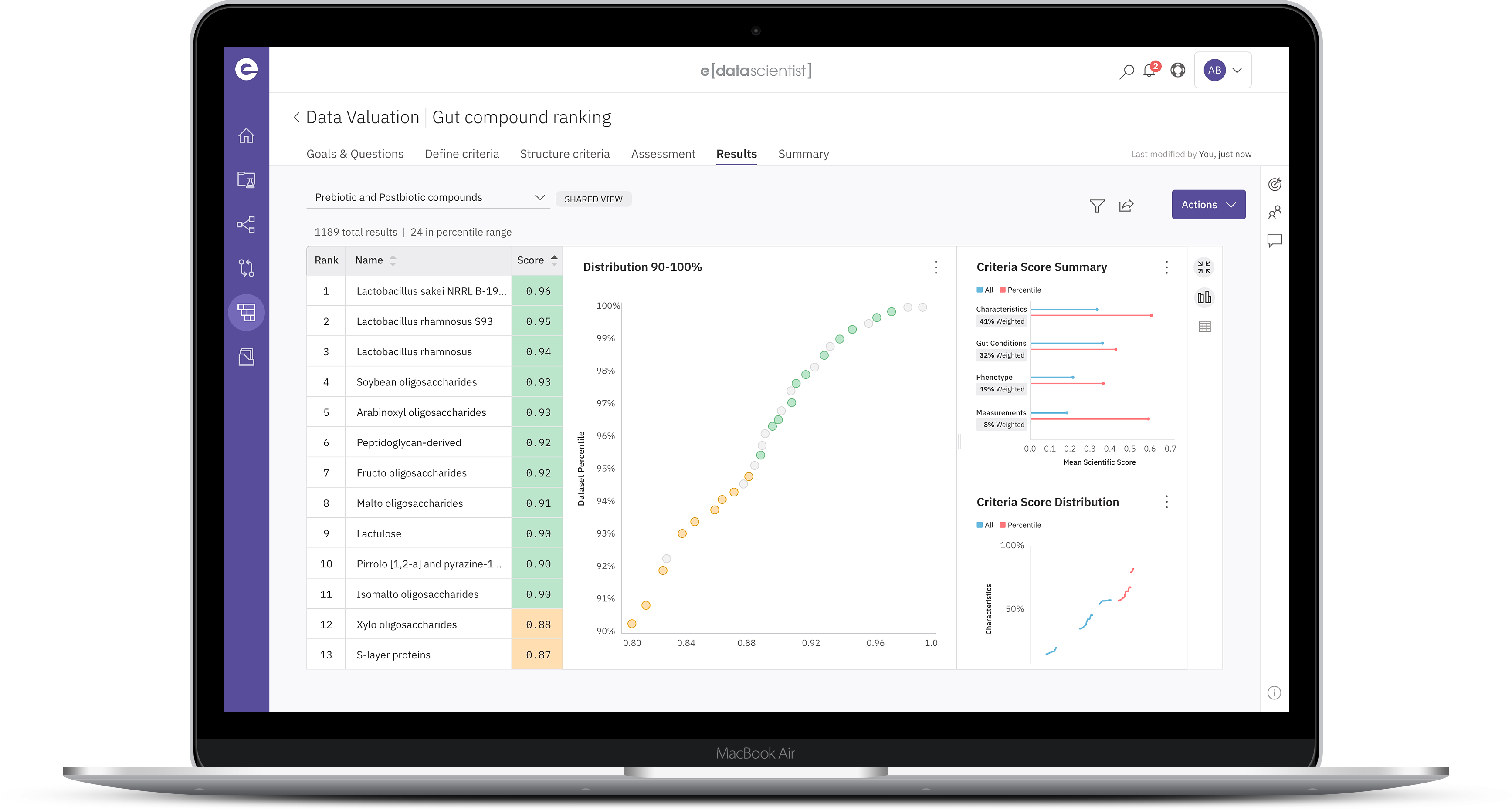
Compose robust low-code applications covering a range of business needs. Extend e[datascientist] to deliver custom capabilities and experiences.
Network Life Sciences Platform
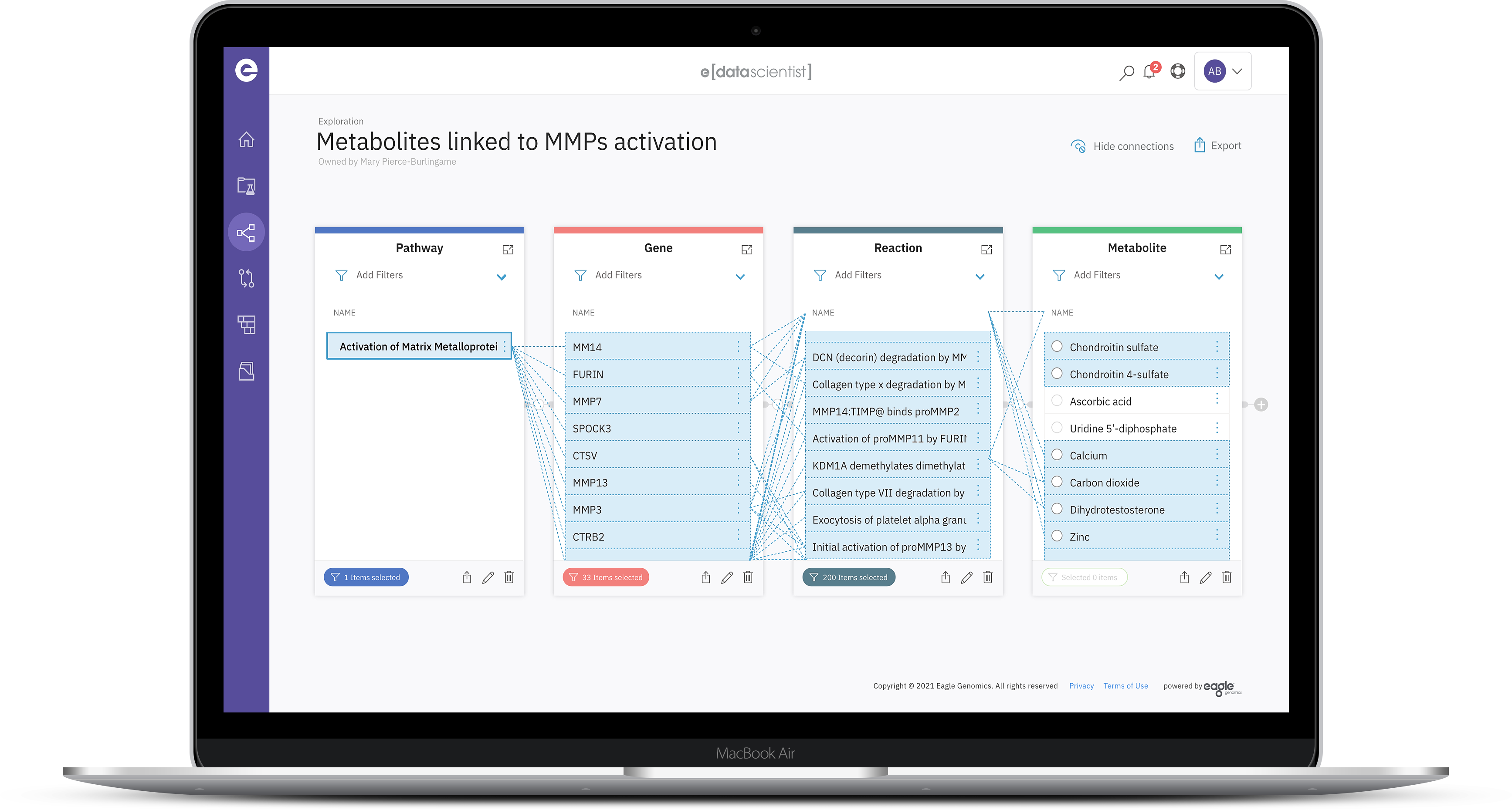
Leverage network science, AI and hypergraph technologies to place data at the heart of innovation.
Trusted Data Fabric
Construct and navigate a unified data fabric and transcend legacy data infrastructure.
INTERNAL DATA
Maximize yield on data

SEMANTIC DATA ACCESS LAYER
Extensive, robust and reliable data models
EXTERNAL DATA
Universe of human and microbial data