
Apr 24, 2020 12:00:00 AM
COVID-19 response initiatives from all over the world including the COVID-19 Genomics UK Consortium, the US-led COVID-19 Open Research Dataset (CORD-19) and the European COVID-19 Data Platform, have been formed to address and overcome the significant data sharing challenges associated with enabling global research cooperation. This already represents a step change in willingness and ability to share data quickly and at scale. It represents a good start; however, lack of unification and collaboration mechanisms will continue to impede progress beyond these initiatives.
In a climate where the majority are forced to work from home, across multiple industries, R&D practices in life sciences have been severely compromised or even halted, with many scientists no longer having access to labs. The world’s sudden change of circumstance has raised the question - how can organisations maintain momentum, continue to innovate and enable their scientists to drive research forward?
Before the crisis, companies focused on innovation were hampered by industry and organisational structure and culture, with their deeply grooved silos, hindering agility and collaboration. Companies would struggle to experiment at a pace that matched the rate of change around them and they could not easily embrace the bold action needed to move quickly from piloting initiatives to scaling the successful ones. The current challenge is changing that.
The solution is in a practice that is gradually being accepted as the future of scientific discovery – “the digital reinvention of life sciences R&D”.
Data is the currency for scientific research and development and the coronavirus global health crisis only highlights the necessity for a solution that enables scientists to continue to work on new breakthroughs and discoveries remotely, but also collaboratively, leveraging the wealth of data already available.
Coronavirus urgency
The White House recently joined a number of institutions in issuing a call to action to the USA’s artificial intelligence experts to develop new text and data mining techniques that can help the science community answer high-priority scientific questions related to COVID-19, stating that: “Decisive action from America’s science and technology enterprise is critical to prevent, detect, treat, and develop solutions to COVID-19.”
Bill Gates also in a recent appeal to America’s top scientists has said: “Today, we have an opportunity with the evolution of tools like AI and gene-based technologies to develop a new generation of health solutions that can benefit everyone, everywhere, in particular to make sense of complex biological systems and accelerate the discovery of therapeutics to improve health”
The promise is that these initiatives could have a profound effect on the ability of manufacturers to identify molecules, biomarkers, protective antigens with the highest probability of successful development and to identify failures earlier.
To enable such a vision, data will be required to flow freely among functions within pharmaceutical companies as well as to partners such as academia and contract research organisations, substantially speeding analysis and value generation.
As has already been demonstrated from the earliest stages of the current pandemic, the ability for scientists to quickly access and interpret disparately stored data across global locations is crucial. Some of the first actions of the World Health Organisation were to mine existing global drug data repositories to identify anti-viral treatments that could be efficacious against the symptoms and effects of COVID-19. Since then we have seen a rush of companies vectoring their activities to evaluate a range of drugs to target the disease but these efforts have been hindered by availability of data and mechanisms to unify and explore disparate data from a range of sources.
From a virus that doesn’t trigger the same response from every host, it was also vital to quickly understand the pre-existing traits and co-morbidities that cause the virus to have a more extreme impact on some than others. Such indications could be more quickly identified if a data-driven ‘virtual’ cohort of patients which transcends the borders of all affected countries, existed.
These are just two examples in which prompt access to unified data can save lives.
However, as recognised by Trevor Mundel, President of Global Health at the Bill Gates Foundation, currently, “geography stands in the way.” There isn’t yet the ability to access globally collected datasets from a central portal, and nor are these data standardised, comparable and therefore effectively interpretable.
The data challenge
The challenge to achieve such a library of useful data that is easily navigable (particularly during crises when time is so much of the essence) is significant.
It firstly requires industry and institution-wide standardisation of data across multiple omics, real world and clinical data.
While this agreement on standardisation remains a work in progress, relevant data need to be identified, curated and linked so that, where previously siloed, datasets are unified and therefore comparable and useful to scientists. Identification and prioritisation of relevant data is in itself a significant challenge, particularly where data exists but is not known to a scientist, team or organisation. This previously unconsidered (dark) data could, however, hold the key to new insight.
The curated, prioritised data must then be catalogued and platformatised to enable access on a global scale, allowing scientists from research organisations, pharmaceuticals, academia and private companies to access the same rich, accurate and up-to-date data resource. To bridge the conversation between the data and the scientist, the platform interface must be as accessible and intuitive as possible, without a requirement for data science expertise. More importantly, the whole process of data identification, curation, navigation and exploration needs to be systematised – through the application of data science to the data science workflow – if we are to unlock the value that data sharing promises to deliver.
Systems biology
Combining a broad range of multi-omics data (e.g. virome, microbiome, genomic…) with real world data such as patient geography, lifestyle, records of mild health issues etc. is particularly significant in the case of a relatively unknown coronavirus, where the risk profiles which signpost the likelihood of disease progression to COVID-19 are little understood.
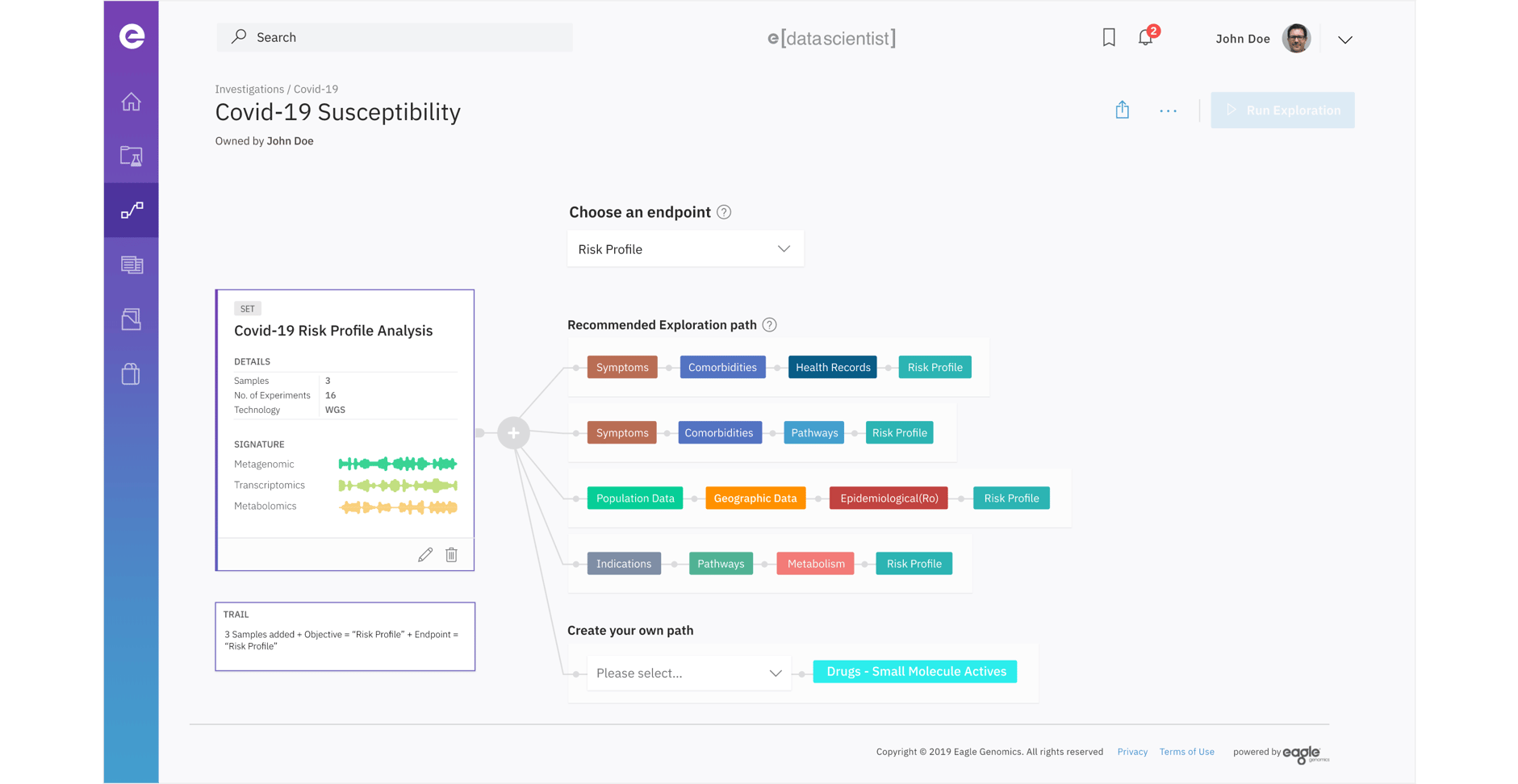
e[datascientist] COVID-19 Risk Profile Exploration
For example, it is possible to conceive that a person’s previous (but undiagnosed) infection by a less severe coronavirus has caused a more severe reaction to this new strain. Or indeed, on looking further into other possible relating factors such as the hosts’ microbiome, a particular microbiome profile found in the lung may correlate with an increased likelihood of the patient developing COVID-19 from the virus.
In fact, it is likely to be a systemic combination of factors that lead to an increased risk of suffering more severely from the virus. Revealing these correlations within these systems as quickly as possible informs further research into possible causation, which can be directly translated into treatments.
Power in data
In any scenario, the power is in the knowledge extracted from existing data. In the case of this coronavirus and COVID-19, the ability to predict the likelihood of a patient to be asymptomatic, or to require hospitalisation and the need for ventilation from a detailed risk profile empowers health professionals to make informed decisions that would no-doubt save lives, and ease the intolerable pressures on health services across the world.
It is this concept of harnessing the power of existing data that must be embraced and adopted beyond this crisis. This also provides a solution to the current challenge, which sees many scientists forced out of labs and working from home. The data to solve some of the grand life sciences challenges is likely already out there, it requires enterprise class solutions for unification, navigation, exploration and collaboration in order for it to yield up its secrets.
This is the first of our series of blogs on COVID-19, look out for future blogs discussing opportunities for data-driven discovery and collaboration in the current global research effort.